



On Variational Bounds of Mutual Information
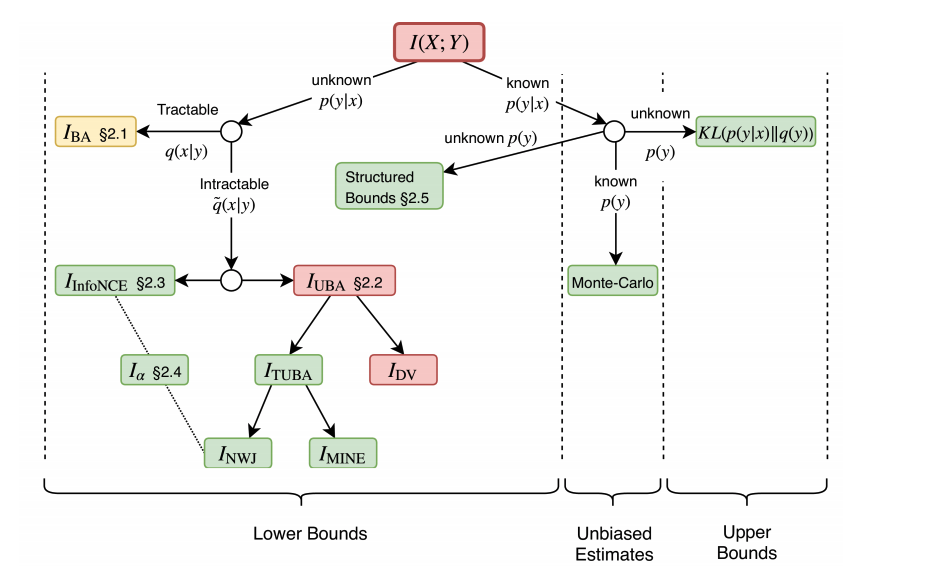
Estimating and optimizing Mutual Information (MI) is core to many problems in machine learning; however, bounding MI in high dimensions is challenging. To establish tractable and scalable objectives, recent work has turned to variational bounds parameterized by neural networks, but the relationships and tradeoffs between these bounds remains unclear. In this work, we unify these recent developments in a single framework. We find that the existing variational lower bounds degrade when the MI is large, exhibiting either high bias or high variance. To address this problem, we introduce a continuum of lower bounds that encompasses previous bounds and flexibly trades off bias and variance. On high-dimensional, controlled problems, we empirically characterize the bias and variance of the bounds and their gradients and demonstrate the effectiveness of our new bounds for estimation and representation learning.
