



On the number of response regions of deep feed forward networks with piece-wise linear activations
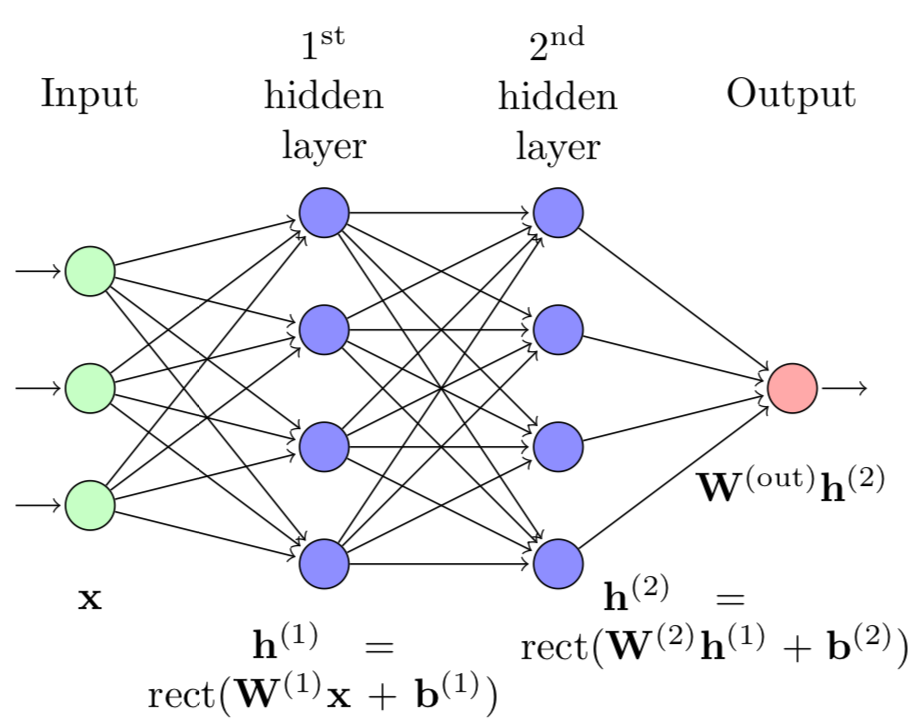
This paper explores the complexity of deep feedforward networks with linear pre-synaptic couplings and rectified linear activations. This is a contribution to the growing body of work contrasting the representational power of deep and shallow network architectures. In particular, we offer a framework for comparing deep and shallow models that belong to the family of piecewise linear functions based on computational geometry. We look at a deep rectifier multi-layer perceptron (MLP) with linear outputs units and compare it with a single layer version of the model. In the asymptotic regime, when the number of inputs stays constant, if the shallow model has kn hidden units and n0 inputs, then the number of linear regions is O(kn0nn0). For a k layer model with n hidden units on each layer it is Ω(⌊n/n0⌋k−1nn0). The number ⌊n/n0⌋k−1 grows faster than kn0 when n tends to infinity or when k tends to infinity and n≥2n0. Additionally, even when k is small, if we restrict n to be 2n0, we can show that a deep model has considerably more linear regions that a shallow one. We consider this as a first step towards understanding the complexity of these models and specifically towards providing suitable mathematical tools for future analysis.
Reference
https://arxiv.org/abs/1312.6098
