



Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks
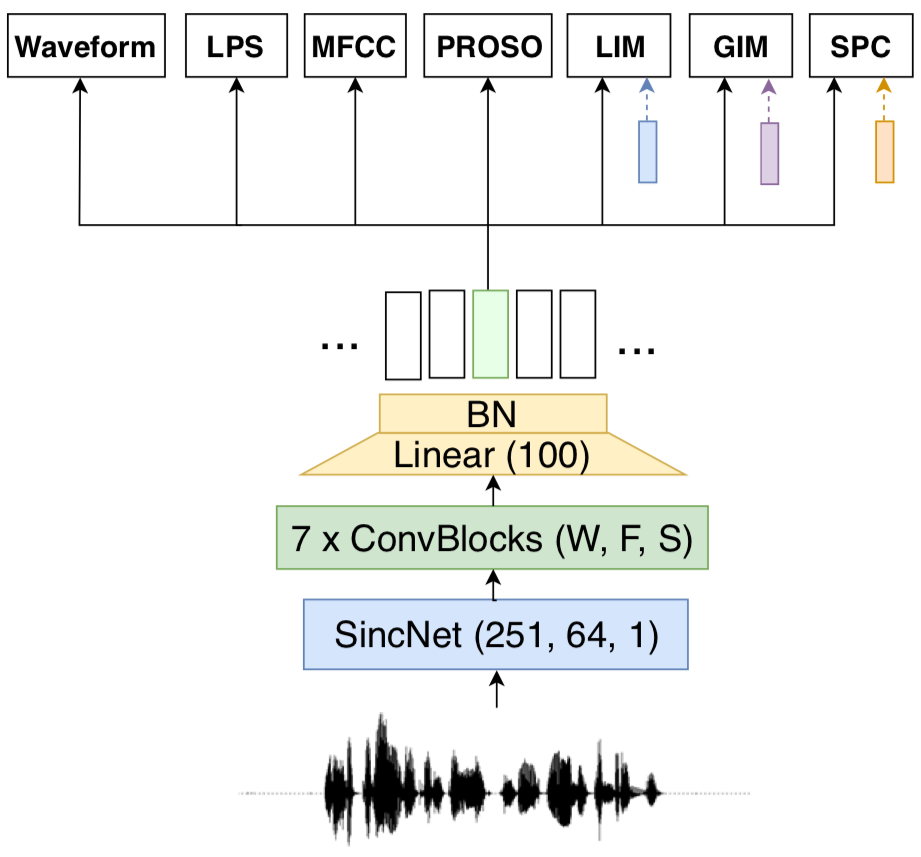
Learning good representations without supervision is still an open issue in machine learning, and is particularly challenging for speech signals, which are often characterized by long sequences with a complex hierarchical structure. Some recent works, however, have shown that it is possible to derive useful speech representations by employing a self-supervised encoder-discriminator approach. This paper proposes an improved self-supervised method, where a single neural encoder is followed by multiple workers that jointly solve different self-supervised tasks. The needed consensus across different tasks naturally imposes meaningful constraints to the encoder, contributing to discover general representations and to minimize the risk of learning superficial ones. Experiments show that the proposed approach can learn transferable, robust, and problem-agnostic features that carry on relevant information from the speech signal, such as speaker identity, phonemes, and even higher-level features such as emotional cues. In addition, a number of design choices make the encoder easily exportable, facilitating its direct usage or adaptation to different problems.
Reference
https://arxiv.org/abs/1904.03416

