



Efficient Exact Gradient Update for training Deep Networks with Very Large Sparse Targets
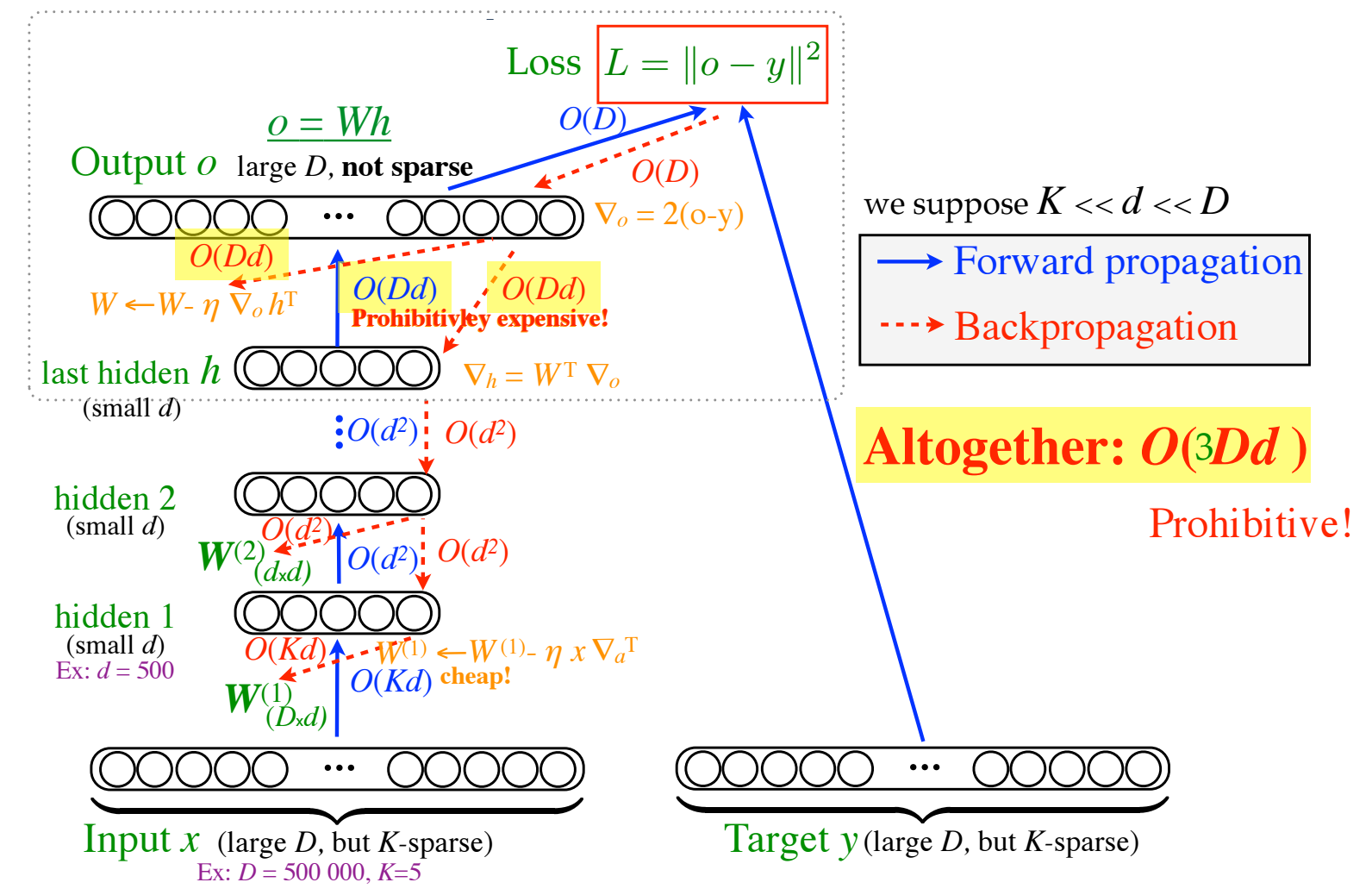
An important class of problems involves training deep neural networks with sparse prediction targets of very high dimension D. These occur naturally in e.g. neural language models or the learning of word-embeddings, often posed as predicting the probability of next words among a vocabulary of size D (e.g. 200 000). Computing the equally large, but typically non-sparse D-dimensional output vector from a last hidden layer of reasonable dimension d (e.g. 500) incurs a prohibitive O(Dd) computational cost for each example, as does updating the D x d output weight matrix and computing the gradient needed for backpropagation to previous layers. While efficient handling of large sparse network inputs is trivial, the case of large sparse targets is not, and has thus so far been sidestepped with approximate alternatives such as hierarchical softmax or sampling-based approximations during training. In this work we develop an original algorithmic approach which, for a family of loss functions that includes squared error and spherical softmax, can compute the exact loss, gradient update for the output weights, and gradient for backpropagation, all in O(d^2) per example instead of O(Dd), remarkably without ever computing the D-dimensional output. The proposed algorithm yields a speedup of D/4d , i.e. two orders of magnitude for typical sizes, for that critical part of the computations that often dominates the training time in this kind of network architecture.
Reference
Pascal Vincent, Alexandre de Brébisson, Xavier Bouthillier, Exact Gradient Update for training Deep Networks with Very Large Sparse Targets, in: Advances in Neural Information Processing Systems 28 (NIPS), pp. 1108-1116, 2015


