



Sep
2015
Describing Multimedia Content using Attention-based Encoder–Decoder Networks
Sep
2015
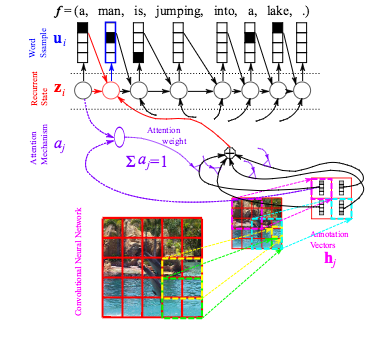
Whereas deep neural networks were first mostly used for classification tasks, they are rapidly expanding in the realm of structured output problems, where the observed target is composed of multiple random variables that have a rich joint distribution, given the input. We focus in this paper on the case where the input also has a rich structure and the input and output structures are somehow related. We describe systems that learn to attend to different places in the input, for each element of the output, for a variety of tasks: machine translation, image caption generation, video clip description and speech recognition. All these systems are based on a shared set of building blocks: gated recurrent neural networks and convolutional neural networks, along with trained attention mechanisms. We report on experimental results with these systems, showing impressively good performance and the advantage of the attention mechanism

Reference
Kyunghyun Cho, Aaron Courville and Yoshua Bengio, Describing Multimedia Content Using Attention-Based Encoder-Decoder Networks, in: IEEE Transactions on Multimedia, vol. 17, no. 11, pp. 1875-1886, 2015


