




Note de la rédaction: ce billet a été publié à l’origine sur le site Web personnel de l’auteur et a été revu et adapté pour le blogue de Mila avec le consentement de l’auteur. Ce qui suit est le résumé et les questions-réponses d’un article récent sur le même sujet co-écrit par Harry Mingde Zhao et d’autres chercheurs de Mila.
[Accepté au NeurIPS 2021] Nous introduisons des biais inductifs dans l’apprentissage par renforcement, inspirés des fonctions cognitives supérieures de l’humain. Ces contraintes architecturales permettent à l’agent de planification de se concentrer sur les parties intéressantes de l’état à chaque étape des trajectoires futures imaginées.
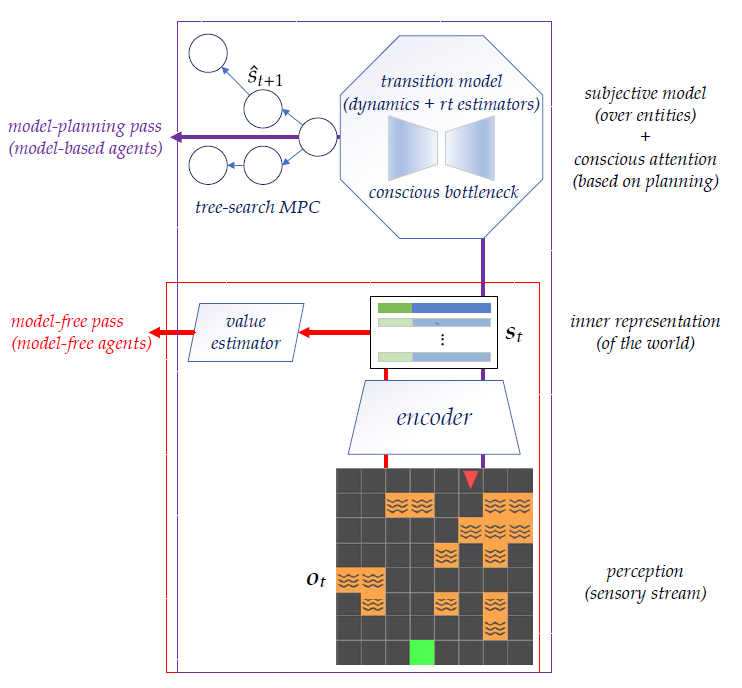
Figure 1. Aperçu de la conception globale
Par exemple, lors de la planification d’un trajet entre le bureau ou l’hôtel et l’aéroport dans une ville inconnue, nous nous concentrons généralement sur un petit sous-ensemble de variables pertinentes, comme le changement de position ou la présence de trafic. Une hypothèse intéressante quant à la manière dont nous généralisons cette aptitude à planifier un trajet d’une situation à l’autre suppose qu’elle pourrait découler d’un calcul associé au traitement conscient de l’information. L’attention consciente se concentre sur quelques éléments pertinents de l’environnement, déterminés à partir d’une représentation abstraite interne du monde. Ce modèle, également connu sous le nom de conscience au sens premier (C1), a été développé pour représenter l’adaptabilité et l’efficacité exceptionnelles de l’apprentissage chez les humains. L’une des principales caractéristiques du traitement conscient de l’information est qu’il implique un goulet d’étranglement, qui oblige une personne à gérer les relations entre un petit nombre de variables de l’environnement à la fois. Bien que cette attention sur un petit sous-ensemble d’informations disponibles semble un facteur limitatif, elle peut améliorer la généralisation hors distribution (OOD) et la généralisation systématique dans d’autres situations où les éléments ignorés sont différents, mais ne sont jamais pertinents. Dans cet article, nous proposons une architecture qui nous permet d’encoder certaines de ces idées dans le comportement des agents.
Nous proposons de nous inspirer de la conscience humaine pour construire une architecture qui apprend un espace d’état utile et concentre son attention sur un petit ensemble de variables à tout moment. Cette idée de « planification partielle » est possible grâce aux techniques modernes d’apprentissage par renforcement profond. Plus précisément, nous proposons un apprentissage par renforcement profond basé sur un modèle de bout en bout (MBLR). L’agent MBRL dans un espace latent n’a pas à reconstruire les observations, comme dans la plupart des travaux existants, et utilise la commande prédictive (MPC) pour la planification des décisions. À partir d’une observation, l’agent encode un ensemble d’objets comme un état, avec un mécanisme de goulet d’étranglement (l’attention sélective) pour planifier à partir de sous-ensembles sélectionnés de l’état (voir section 4 de l’étude). Nos expériences montrent que les biais inductifs améliorent une forme spécifique de généralisation OOD, où des dynamiques cohérentes sont préservées dans des environnements apparemment différents (Sec. 5).
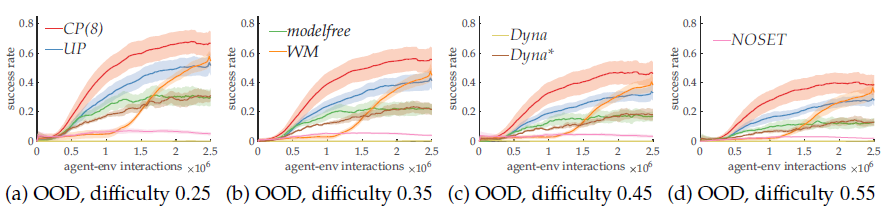
Figure 2. Expérience montrant que la capacité de généralisation OOD du goulet d’étranglement est prometteuse
Questions et réponses intéressantes :
Q : Pouvez-vous définir ce que vous entendez par OOD ?
R : Nous nous concentrons sur les compétences transférables dans des environnements totalement différents ayant une dynamique cohérente, ce qui signifie que la dynamique de l’environnement est suffisante pour résoudre les tâches de la distribution, et l’évaluation hors distribution est préservée de manière cohérente. En même temps, le reste peut être très différent. Intuitivement, nous voulons entraîner notre agent pour qu’il soit capable de planifier des trajets dans une ville d’origine et nous nous attendons à ce que cette capacité soit généralisée à d’autres municipalités. Les lieux peuvent être très différents, mais la capacité à planifier des itinéraires dépend de connaissances qui sont assez universelles.
Q : Pourquoi utilisez-vous un cadre non statique où les environnements changent à chaque épreuve ?
R : Intuitivement, l’agent n’a pas besoin de comprendre la dynamique de la tâche si l’environnement est fixe : mémoriser où aller et où ne pas aller est bien plus facile que de raisonner sur ce qui peut arriver. Avec les différentes épreuves, l’agent doit apprendre et comprendre la dynamique de l’environnement, ce qui est crucial pour l’évaluation OOD.
Q : Comment éviter l’effondrement de la représentation de l’état ?
R : En dehors du signal d’entraînement pour la dynamique, dont l’existence exclusive pourrait provoquer un effondrement, tous les autres signaux d’entraînement passent par le goulet d’étranglement de l’encodeur : la représentation est donc également façonnée par les signaux TD, les signaux de prédiction de la récompense. Mentionnons également que les régularisations participent également à ce processus.
Q : Pourquoi ne pas utiliser des architectures plus riches pour les expériences ?
R : Étant donné que l’agent proposé comporte déjà de nombreux composants, nous utilisons les tailles d’architecture minimales qui permettent d’obtenir de bonnes performances en apprentissage par renforcement en fonction de nos paramètres de test afin d’isoler les facteurs qui pourraient influencer les comportements de l’agent.
Q : Pourquoi ne pas utiliser la recherche arborescente Monte Carlo comme méthode de recherche pour la planification des décisions ?
R : Contrairement à AlphaGo, qui utilise cette méthode, notre architecture est basée sur le produit de base DQN. DQN utilise une politique gourmande basée sur l’estimation des valeurs au lieu d’une politique paramétrée comme l’architecture acteur-critique utilisée dans AlphaGo. La politique du DQN est déterministe par rapport aux valeurs estimées ; par conséquent, la planification ne peut pas tirer suffisamment parti de la recherche arborescente Monte Carlo basée sur les échantillons.
Pour lire l’article sur arXiv, cliquez ici.
Pour consulter l’article original du blogue, cliquez ici.
Coauteurs du document
Harry Mingde Zhao, doctorant, Université McGill/Mila
Zhen Liu, doctorant, Université de Montréal/Mila
Sitao Luan, doctorant, Université McGill/Mila
Shuyuan Zhang, doctorant, Université McGill/Mila
Doina Precup, professeure agrégée, Université McGill/Mila
Yoshua Bengio, professeur titulaire, Université de Montréal/Mila
Auteur
