




Note de la rédaction : Ce billet de blogue a été rédigé d’après un article publié à l’occasion de la Conference on Robot Learning (CoRL) 2021. Pour en savoir plus, nous vous invitons à consulter le site Web du projet.
L’apprentissage par renforcement fournit un cadre conceptuel permettant aux agents autonomes d’apprendre par l’expérience, de manière analogue au dressage d’un animal de compagnie à l’aide de récompenses. Mais les applications pratiques de l’apprentissage par renforcement sont souvent loin d’être naturelles : au lieu d’utiliser un apprentissage par renforcement pour apprendre par essais et erreurs en essayant d’effectuer la tâche souhaitée, les applications d’apprentissage par renforcement typiques utilisent une phase d’entraînement distincte (habituellement simulée). Par exemple, AlphaGo n’a pas appris à jouer à Go en affrontant des milliers d’humains, mais plutôt en jouant contre lui-même en mode simulation. Bien que ce type d’entraînement simulé soit attrayant pour les jeux où les règles sont parfaitement connues, son application à des domaines du monde réel tels que la robotique peut nécessiter un éventail d’approches complexes, telles que l’utilisation de données simulées ou l’instrumentation d’environnements du monde réel de diverses façons pour rendre l’entraînement possible dans des conditions de laboratoire. Pouvons-nous plutôt concevoir des systèmes d’apprentissage par renforcement pour les robots qui leur permettent d’apprendre de façon spontanée, tout en effectuant la tâche qu’ils doivent accomplir? Dans ce billet de blogue, nous discuterons de ReLMM, un système que nous avons développé et qui apprend à nettoyer une pièce directement avec un vrai robot par l’apprentissage continu.
 |
 |
 |
 |
Nous évaluons notre méthode sur différentes tâches dont la difficulté varie. La première tâche consiste à ramasser des formes indistinctes blanches uniformes qui se trouvent sur le sol sans qu’il y ait d’obstacles, tandis que d’autres pièces comportent des objets de formes et de couleurs diverses, des obstacles qui augmentent la difficulté de navigation et cachent les objets et des tapis à motifs qui rendent la visibilité des objets sur le sol difficile.
Pour permettre l’entraînement « spontané » dans le monde réel, la difficulté de recueillir davantage d’expérience est prohibitive. Si nous pouvons faciliter l’entraînement dans le monde réel, en rendant le processus de collecte de données plus autonome, c’est-à-dire sans avoir recours à une surveillance ou à une intervention humaine, nous pouvons bénéficier davantage de la simplicité des agents qui apprennent par l’expérience. Dans le cadre de ce travail, nous concevons un système d’entraînement de robot mobile « spontané » pour le nettoyage en apprenant à saisir des objets qui se trouvent dans différentes pièces.
Leçon 1 : les avantages des politiques modulaires pour les robots.
Les gens ne naissent pas un jour et passent des entrevues d’emploi le lendemain. Une personne doit passer par l’apprentissage de nombreux niveaux de tâches avant de pouvoir postuler à un emploi; nous commençons par les tâches les plus faciles, puis nous nous attaquons peu à peu à celles plus difficiles. Dans ReLMM, nous utilisons ce concept en permettant aux robots d’exercer des compétences réutilisables communes, comme la préhension, en les encourageant tout d’abord à exercer ces compétences en priorité avant d’apprendre d’autres compétences venant plus tard, comme la navigation. Apprendre de cette façon présente deux avantages pour la robotique. Le premier avantage est que lorsqu’un agent se concentre sur l’apprentissage d’une compétence, il est plus efficace pour recueillir des données autour de la distribution de l’état local pour cette compétence. Cela est illustré dans la figure ci-dessous où nous avons évalué la quantité d’expérience de préhension priorisée nécessaire pour que l’entraînement de manipulation mobile soit efficace. Le deuxième avantage d’avoir une approche d’apprentissage à plusieurs niveaux est que nous pouvons inspecter les modèles entraînés pour différentes tâches et leur poser des questions, comme « pouvez-vous saisir tout objet maintenant? », ce qui s’avère utile pour l’entraînement de navigation que nous décrivons dans ce qui suit.
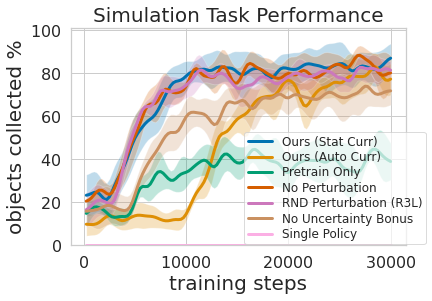
Exercer cette politique à plusieurs niveaux s’est avéré non seulement plus efficace que l’apprentissage des deux compétences en même temps, mais cela a également permis au contrôleur de préhension de façonner la politique de navigation. Avoir un modèle qui estime l’incertitude dans sa réussite de préhension (« Ours » ci-dessous) peut être utilisé pour améliorer l’exploration de navigation en évitant les aires ne comportant pas d’objets saisissables, contrairement à « No Uncertainty Bonus » qui n’utilise pas cette information. Le modèle peut également être utilisé pour réétiqueter les données pendant l’entraînement afin que dans le cas infortuné où le modèle de préhension n’a pas réussi à saisir un objet à sa portée, la politique de préhension puisse toujours fournir un certain signal en indiquant qu’un objet se trouvait là, mais que la politique de préhension n’a pas encore appris à le saisir. De plus, l’apprentissage par modèles modulaires présente des avantages techniques. L’entraînement modulaire permet de réutiliser les compétences qui sont plus faciles à apprendre et peut permettre de construire des systèmes intelligents une pièce à la fois. Cela est avantageux pour de nombreuses raisons, y compris l’évaluation et la compréhension de la sécurité.
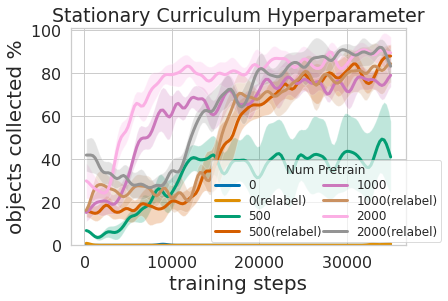
Leçon 2 : les systèmes d’apprentissage sont plus performants que les systèmes codés à la main, avec du temps.
De nombreuses tâches robotiques que nous observons de nos jours peuvent être résolues à différents niveaux de réussite à l’aide de contrôleurs conçus à la main. Pour notre tâche de nettoyage de pièce, nous avons développé un contrôleur conçu à la main qui localise les objets en utilisant un regroupement d’images et qui se tourne vers l’objet détecté le plus proche à chaque étape. Ce contrôleur conçu de manière experte fonctionne très bien sur les chaussettes en boule visuellement proéminentes, et il suit un parcours raisonnable pour contourner les obstacles, mais il ne peut pas apprendre un parcours optimal pour ramasser les objets rapidement et il a de la difficulté avec les pièces diversifiées sur le plan visuel. Comme le montre la vidéo 3 ci-dessous, la politique prédéfinie est distraite par le tapis à motifs blanc lorsqu’elle essaie de localiser plus d’objets blancs à saisir.
1)  |
2)  |
3)  |
4) 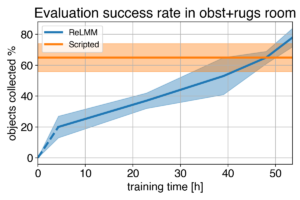 |
Nous montrons une comparaison entre (1) notre politique au début de l’entraînement (2) notre politique à la fin de l’entraînement (3) la politique prédéfinie. Dans (4), nous pouvons voir la performance du robot s’améliorer au fil du temps et, ultimement, dépasser celle de la politique prédéfinie quant à la préhension rapide des objets qui se trouvent dans la pièce.
Étant donné que nous pouvons utiliser des experts pour coder ce contrôleur conçu à la main, quel est le but de l’apprentissage? Une limite importante des contrôleurs conçus à la main est qu’ils sont réglés pour une tâche particulière, par exemple, saisir des objets blancs. Lorsque divers objets aux couleurs et aux formes différentes sont introduits, il se peut que le réglage initial ne soit plus optimal. Plutôt que nécessiter davantage d’ingénierie manuelle, notre méthode basée sur l’apprentissage est en mesure de s’adapter à diverses tâches en recueillant sa propre expérience.
Cependant, la leçon la plus importante à retenir est que même si le contrôleur conçu à la main a la capacité d’effectuer la tâche, s’il a assez de temps, l’agent apprenant finit par le dépasser. Ce processus d’apprentissage est autonome en lui-même et se déroule pendant que le robot effectue son travail, ce qui le rend relativement peu coûteux. Cela montre la capacité des agents apprenants, qui peut également être considéré comme étant un moyen général d’effectuer un processus de « réglage manuel par un expert » pour tout type de tâche. Les systèmes d’apprentissage ont la capacité de créer l’algorithme de commande au complet pour le robot et ne se limitent pas au réglage de quelques paramètres dans un script. L’étape clé de ce travail permet à ces systèmes d’apprentissage dans le monde réel de recueillir de façon autonome les données nécessaires à la réussite des méthodes d’apprentissage.
Vidéo connexe
